LVS 基础知识
LVS 介绍
LVS(Linux Virtual Server)即Linux虚拟服务器,通常是实现虚拟网络服务负载调度的主要技术,而且是目前IP负载调度器中实现技术中效率最高的。在已有的IP负载均衡调度器技术中,主要有通过网络地址转换(Network Address Translation)将一组服务器构成一个高性能、高可用的虚拟服务器,也就是VS/NAT技术。在分析VS/NAT的缺点和网络服务的非对称性的基础上,又提出了通过IP隧道实现虚拟服务器的方法VS/TUN,和通过直接路由实现虚拟服务器的方法VS/DR,他们可以极大的提高系统的伸缩性。这三种技术是LVS集群中实现的三种IP负载均衡技术。
LVS 优点
- 抗负载能力强,工作在传输层上仅分发,没有流量的产生,它在所有负载均衡软件里的性能最强,对于内存和CPU资源消耗较低。
- 配置性比较低,相比其他没有过多的配置,不容易出错。
- 工作稳定,本身抗负载能力很强,自身有完整的双机热备方案(LVS KeepAlived主备模式)。
- 无流量,无需建立连接,只分发数据包,保证IO的性能不会受到大流量影响。
- 应用范围广,工作在传输层,可以对几乎所有应用负载均衡。
用来顶住前端的大流量访问压力。
LVS 缺点
- 因为没有解析到上层,所以要求被负载的服务器一定是镜像服务器。
- 软件本身不支持正则表达式处理,不能做动静分离。
- 对于大型应用体系下,单纯依靠LVS KeepAlived实现复杂。
网络模型:
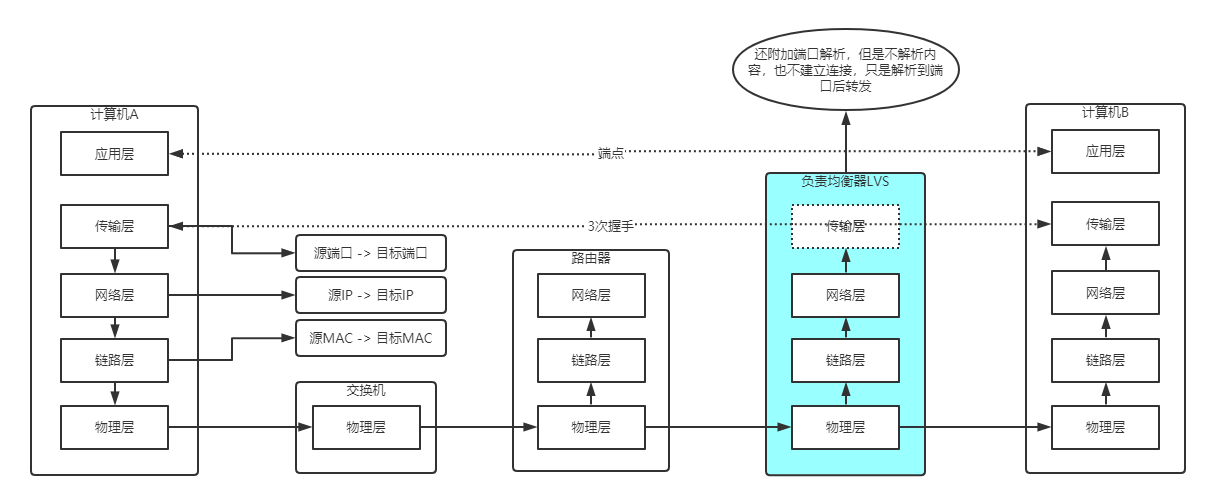
本身比路由器多了一层传输层,但是却并不是完整的传输层,因为传输层应该是建立连接的(TCP),但是LVS并没有建立连接,仅仅解析出访问的端口,就直接回到网络层-链路层-物理层然后转发出去,解析端口的目的是为了识别出同一种服务,然后做负载均衡。
网络拓扑图:
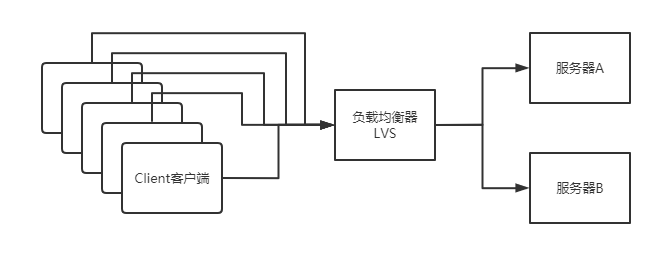
由于LVS不解析到内容,所以代理的服务器A和服务器B应该是同一个服务,是同一个,如果A和B不同,那么客户端在访问的时候,如果期望是访问A的服务,那么给客户端的感觉就是时好时坏。
LVS 工作模式
LVS有三种工作模式,分别具有不同的应用场景和特点。
VS/NAT模式
网络地址转换模式,就类似于一个路由器,将访问地址替换为目标地址。回去时再做一次转换。
NAT过程示意图:
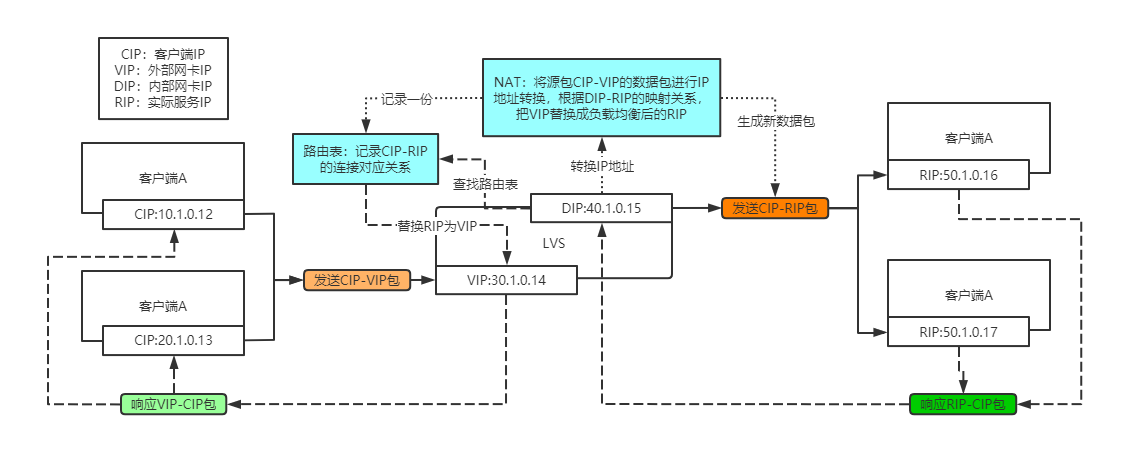
- 客户端发送数据包到LVS上,此时数据包源IP=CIP,目标IP=VIP。
- LVS外部网卡接收到数据包后,根据内部网卡连接的服务器,选择一台的RIP进行替换IP并生成虚拟端口。
- 将CIP-RIP的实际连接和他们的端口维护在自己的路由表中。
- 数据包替换完成后转发给对应的内部服务器(也可以是另外的路由器或交换机或负载均衡器),此时源IP=CIP,目的IP=RIP。
- 内部服务器响应数据包,此时源IP=RIP,目的IP=CIP,原样返回。
- LVS接收到数据包响应后,先去自己的路由表中查找,然后将RIP替换为VIP(端口也还原),此时源IP=VIP,目的IP=CIP。
- 客户端(可能也是路由器或交换机等)接收到数据包后,发送的时候源IP=CIP,目的IP=VIP,接收源IP=VIP,目的IP=CIP,可以接收。
从流程中可以看出,NAT模式中LVS是所有网络连接的通讯桥梁。每次都需要LVS进行解包,改包,发送,回去的时候,又要解包,改包,发送。
优点:
- 实现相对简单。
缺点:
- 服务器带宽瓶颈:每次都要经过它。
- 消耗CPU的计算力:每次都要解包,改包,发包。
VS/TUN模式
为了解决NAT的带宽瓶颈,和CPU的多次计算,不采用每次都走LVS的模式,所以TUN模式下的LVS就是一个领路人,只负责把客户端的数据包路由到对应的服务器上,响应就让对应服务器直接丢回去就行,不需要再走LVS了,这就是IP隧道模式。
TUN过程示意图:
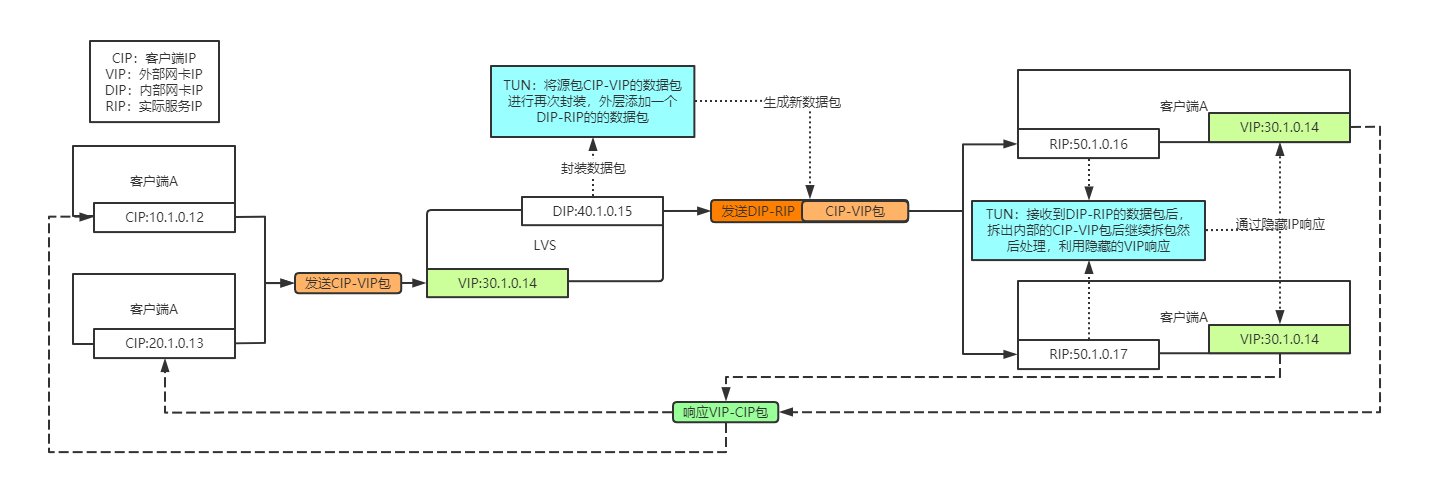
- 客户端发送数据包到LVS上,此时数据包源IP=CIP,目标IP=VIP。
- LVS外部网卡接收到数据包后,根据内部网卡连接的服务器,选择一台的RIP进行再次封包,加一层。
- 数据包封装完成后转发给对应的内部服务器,此时源IP=DIP,目的IP=RIP,内层数据包源IP=CIP,目的IP=VIP。
- 内部服务器接收到数据包后解出DIP-RIP的数据包,然后继续解出内部CIP-VIP的数据包进行处理。
- 处理完成后直接根据隐藏的VIP回复VIP-CIP的数据包回去,不需要封到RIP-DIP的层次。
- 客户端(可能也是路由器或交换机等)接收到数据包后,发送的时候源IP=CIP,目的IP=VIP,接收源IP=VIP,目的IP=CIP,可以接收。
从流程中可以看出,TUN模式中LVS只对请求做了处理,而且是加了一层数据包的包装后,然后发送数据包,响应的时候无需经过LVS处理。
优点:
- 缓解瓶颈:不需要处理响应数据,只需要处理请求数据。
- 缓解CPU的计算力:LVS本身做的事情比较少。
缺点:
- 要求硬件支持IP隧道协议:利用的IP隧道的方式多封装一次包,服务器需要多解一次包。
- 配置复杂:需要配置好隐藏IP,隐藏IP不能是具有ARP的设备,也就是不能有实际的MAC,否则会暴露。
VS/DR模式
为了平衡NAT和TUN模式,DR模式可以说结合了两者的优势,屏蔽了一些缺陷。
DR过程示意图:
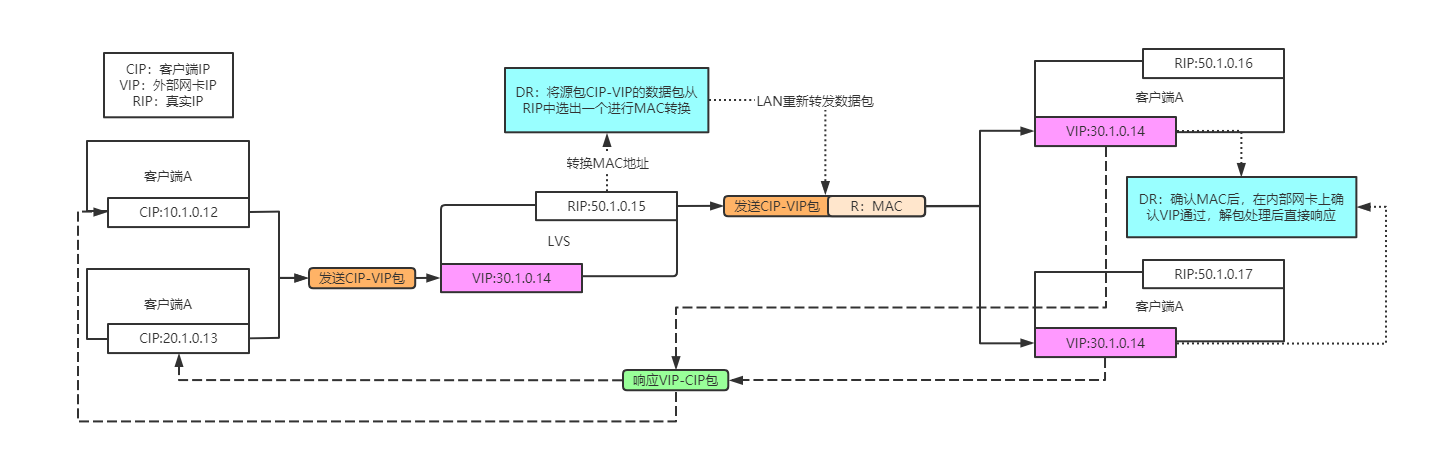
- 客户端发送数据包到LVS上,此时数据包源IP=CIP,目标IP=VIP。
- LVS外部网卡接收到数据包后,根据内部网卡连接的服务器,选择一台的RIP的MAC地址替换,并广播回局域网中。
- 内部服务器发现MAC与自己一致,二层验证通过接收,发现自己的内部网卡VIP与数据包目的IP一致,接收。
- 服务器处理完成后,直接通过内部网卡返回数据包,此时源IP=VIP,目的IP=CIP。
- 客户端(可能也是路由器或交换机等)接收到数据包后,发送的时候源IP=CIP,目的IP=VIP,接收源IP=VIP,目的IP=CIP,可以接收。
从流程中可以看出,DR模式是基于二层来直接修改MAC的,进而来控制数据包的分发,但是由于是LAN数据包发送,所以也有一定的限制,要求LVS与真实服务器在同一个局域网下。
优点:
- 速度极快:基于二层的代理,直接修改MAC。
- 结合了NAT与TUN的优点。
缺点:
- LVS与真实服务器必须位于统一局域网:因为是直接基于MAC的,所以不能走路由设备,否则内部lo网卡无法配置相同的VIP。
LVS 负载策略
不同的工作模式下都需要根据一定的策略去选择如何负载,依靠负载策略去选择合适的RIP或MAC。
轮询调度(Round-Robin Scheduling)
循环调度算法将每个传入请求发送到列表中的下一个服务器。因此,在三个服务器群集(服务器A,B和C)中,请求1将转到服务器A,请求2将转到服务器B,请求3将转到服务器C,请求4将转到服务器A,从而完成循环或“轮循”服务器。它将传入的连接数或每台服务器遇到的响应时间视为平等,将所有真实服务器视为相等。与传统的轮询DNS相比,虚拟服务器具有一些优势。轮询DNS将单个域解析为不同的IP地址,调度粒度基于主机,并且DNS查询的缓存阻碍了基本算法,这些因素导致实际服务器之间出现显着的动态负载不平衡。
加权轮询调度(Weighted Round-Robin Scheduling)
加权循环调度旨在更好地处理具有不同处理能力的服务器。可以为每个服务器分配一个权重,这是一个指示处理能力的整数值。权重较高的服务器比权重较小的服务器首先获得新的连接,权重较高的服务器比权重较小的服务器获得更多的连接,权重相等的服务器获得相等的连接。例如,真实服务器A,B和C分别具有权重4,4,3,在调度周期(mod sum(Wi))中,一个好的调度序列将是AABABCABC。在加权循环调度的实现中,修改虚拟服务器的规则后,将根据服务器的权重生成调度序列。
当真实服务器的处理能力不同时,加权轮询调度比轮询调度要好。但是,如果请求的负载变化很大,则可能导致实际服务器之间的动态负载不平衡。简而言之,有可能将大多数需要较大响应的请求都定向到同一台真实服务器。
实际上,循环调度是加权循环调度的一个特殊实例,其中所有权重均相等。
最少连接调度(Least-Connection Scheduling)
最少连接调度算法将网络连接以最少的已建立连接数定向到服务器。这是动态调度算法之一;因为它需要动态计算每个服务器的活动连接数。对于正在管理具有相似性能的服务器集合的虚拟服务器,当请求的负载变化很大时,最少连接调度可以很好地平滑分发。虚拟服务器将以最少活动连接将请求定向到真实服务器。
乍一看,即使存在具有各种处理能力的服务器,最小连接调度也似乎可以很好地执行,因为速度更快的服务器将获得更多的网络连接。实际上,由于TCP的TIME_WAIT状态,它不能很好地执行。TCP的TIME_WAIT通常为2分钟,在这2分钟内,繁忙的网站通常会收到数千个连接,例如,服务器A的功能是服务器B的两倍,服务器A正在处理数千个请求并将其保存在服务器中。 TCP的TIME_WAIT状态,但是服务器B正在爬网以完成其数千个连接。因此,最少连接调度无法在具有各种处理能力的服务器之间很好地平衡负载。
加权最少连接调度(Weighted Least-Connection Scheduling)
加权的最小连接调度是最小连接调度的超集,您可以在其中为每个真实服务器分配性能权重。权重值较高的服务器将在任何时候获得较大比例的实时连接。虚拟服务器管理员可以为每个真实服务器分配权重,并为每个服务器安排网络连接,其中每个服务器当前活动连接数的百分比与其权重之比。默认权重是1。
加权最小连接调度的工作方式如下:
假设有n个真实服务器,每个服务器i的权重为Wi(i = 1,…,n),活动连接为Ci(i = 1,…,n),则ALL_CONNECTIONS是Ci(i = 1,…,n),下一个网络连接将定向到服务器j,其中(Cj / ALL_CONNECTIONS) / Wj = min{(Ci / ALL_CONNECTIONS) / Wi}(i = 1,…,n),由于ALL_CONNECTIONS在此查找中是一个常量,因此无需将Ci除以ALL_CONNECTIONS,因此可以将其优化为Cj / Wj = min{Ci / Wi}(i = 1,…,n),加权的最小连接调度算法需要比最小连接更多的划分。为了最大程度地减少服务器具有相同处理能力时的调度开销,同时实现了最小连接调度和加权最小连接调度算法。
基于位置的最少连接调度(Locality-Based Least-Connection Scheduling)
基于位置的最小连接调度算法用于目标IP负载平衡。它通常在高速缓存群集中使用。如果服务器处于活动状态且处于负载状态,此算法通常会将发往IP地址的数据包定向到其服务器。如果服务器过载(其活动连接数大于其权重),并且服务器处于半负荷状态,则将加权最少连接服务器分配给该IP地址。
具有复制调度的基于位置的最少连接调度(Locality-Based Least-Connection with Replication Scheduling)
具有复制调度算法的基于位置的最小连接也用于目标IP负载平衡。它通常在高速缓存群集中使用。它与LBLC调度有以下不同:负载平衡器维护从目标到可以为目标提供服务的一组服务器节点的映射。对目标的请求将分配给目标服务器集中的最少连接节点。如果服务器集中的所有节点都超载,则它将拾取群集中的最小连接节点,并将其添加到目标服务器群中。如果在指定时间内未修改服务器集,则从服务器集中删除负载最大的节点,以避免高度复制。
目标哈希调度(Destination Hashing Scheduling)
目标哈希调度算法通过根据服务器的目标IP地址查找静态分配的哈希表来将网络连接分配给服务器。
源哈希调度(Source Hashing Scheduling)
源哈希调度算法通过根据服务器的源IP地址查找静态分配的哈希表来将网络连接分配给服务器。
最短预期延迟调度(Shortest Expected Delay Scheduling)
最短的预期延迟调度算法将网络连接分配给具有最短的预期延迟的服务器。如果将作业发送到第i个服务器,则预期的工作延迟为(Ci +1)/ Ui,其中Ci是第i个服务器上的连接数,而Ui是第i个服务器的固定服务速率(权重) 。
永不排队调度(Never Queue Scheduling)
从不排队调度算法采用两速模型。当有空闲服务器可用时,作业将被发送到空闲服务器,而不是等待快速的服务器。当没有可用的空闲服务器时,作业将被发送到服务器,以使其预期延迟最小化(最短预期延迟调度算法)。
小结
- 目前采用得多的是?
要么是NAT,要么是DR。毕竟越简单的越好,容错率越高越好。
- 调度策略怎么选?
按合适的选…
- 本文链接:https://github.com/moexiong/moexiong.github.io/tree/master/2021/05/15/LVS%20%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。