Kafka 进阶知识
Kafka 日志截断
- HW(High Watermarker):高水位线。所有HW之前的数据都理解为是已经备份的,当所有节点都备份成功,Leader会更新水位线。
- ISR(In-Sync-Replicas):正在同步中的副本。Kafka的Leader会维护一份处于同步的副本集合,如果在
replica.lag.time.max.ms时间内系统没有发送fetch请求,或者依然在发送请求,但是在该限定时间内没有赶上Leader的数据就会被踢出ISR列表。(0.9.0后已废弃的配置:replica.lag.max.messages消息个数限定,这个会导致其他Broker节点频繁加入和退出ISR)- LEO(Log End Offset):日志标识。log and offset标识的是每个分区中最后一条消息的下一个位置,分区中的每个副本都有自己的LEO。
Kafka 高水位
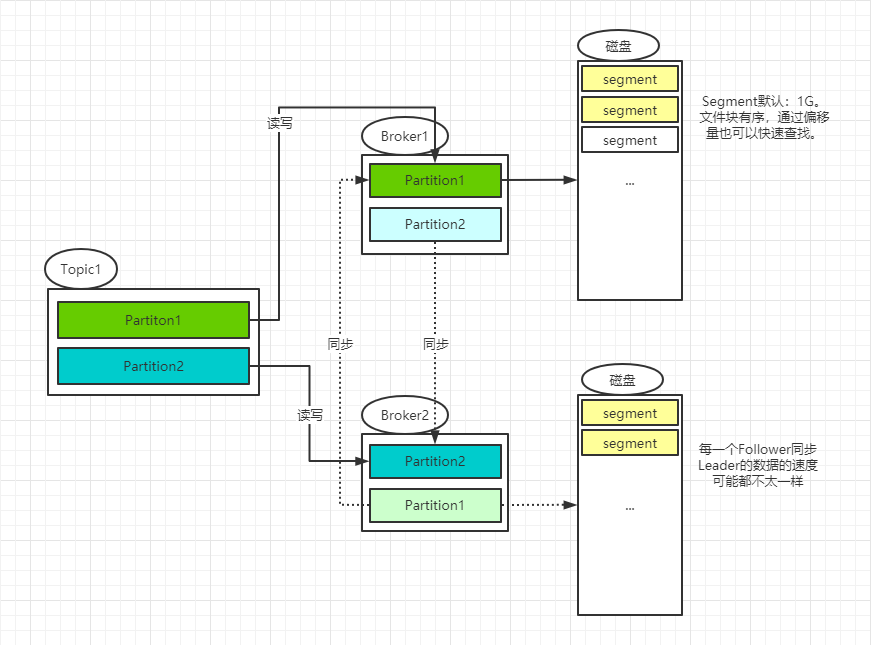
Kafka中的Topic被分为多个分区,分区是按照Segments存储文件块。分区日志是存储在磁盘上的日志序列,Kafka可以保证分区里的事件是有序的。其中Leader负责对应分区的读写,Follower负责同步分区的数据。但是在0.11前,使用HW保证数据的同步,但是基于HW的数据同步可能会导致数据的不一致或者是乱序。
消息同步方式:
高水位的更新:
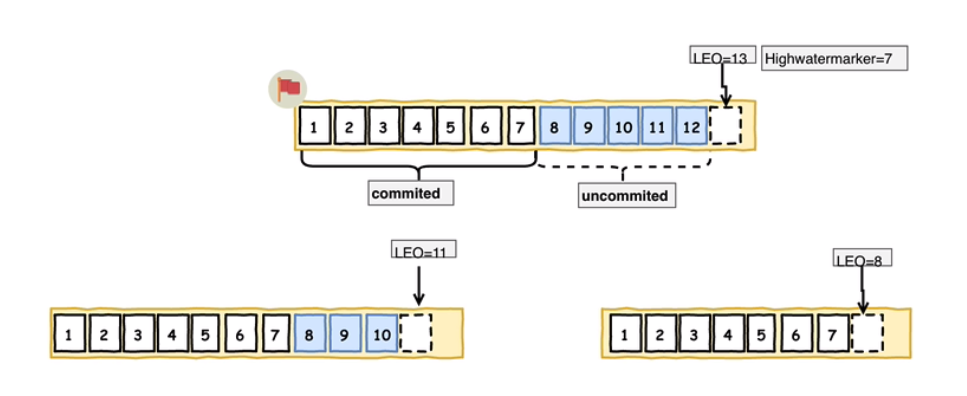
1,2…:代表了上图中的segment。
HW:就是所有副本都同步的公共的位置。
LEO:每个副本的最后一个同步位置。
消息丢失案例(0.11以前的版本,使用需谨慎):
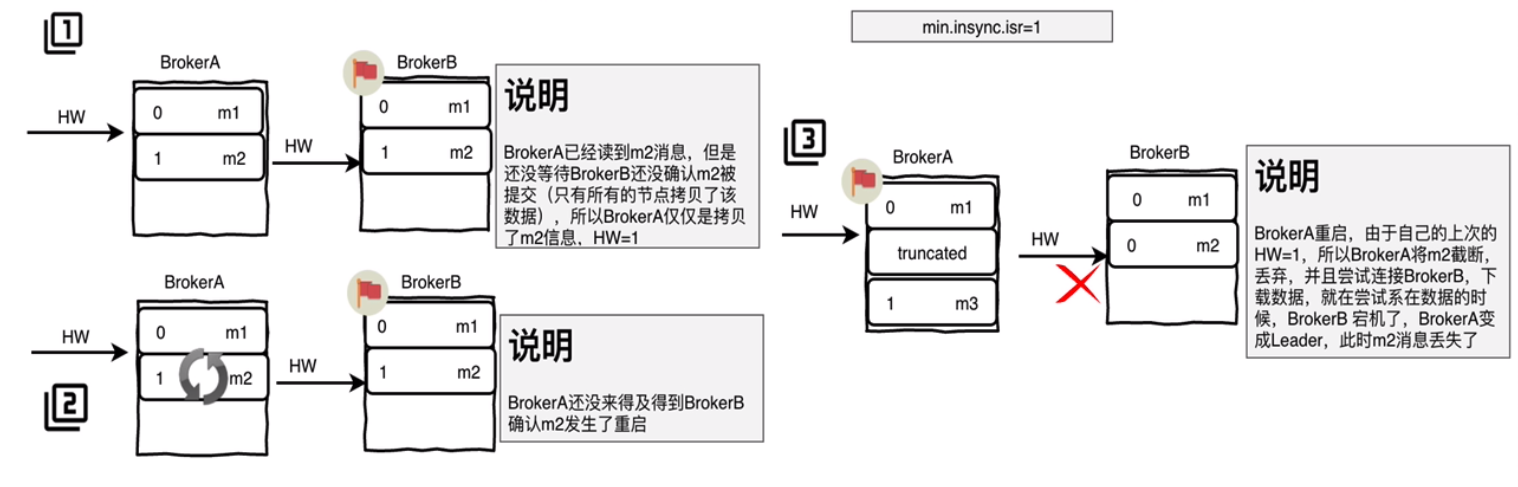
- 副本同步Leader数据m2时,还没有更新自己的HW。
- Leader确认副本已经同步过m2,所以主机更新了自己HW=1。
- 副本突发故障,重启后发现自己的HW=0,丢弃1位置的数据。
- 副本准备连接Leader确认自己的水位线时,Leader也故障。
- 副本被选为Leader,导致1的位置数据变为m3,从而丢失了m2数据。
数据不一致问题(0.11以前的版本,使用需谨慎):
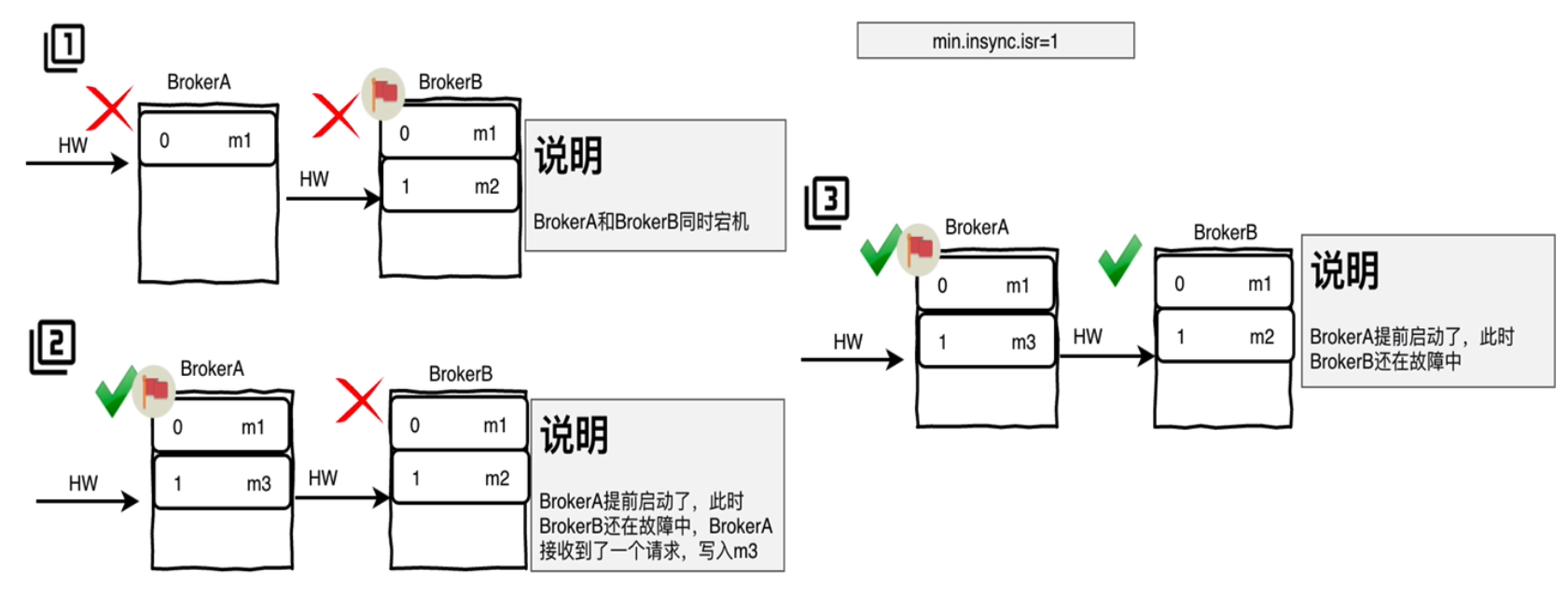
- 副本数据只同步到m1,HW=0,Leader的数据写到m2,HW=1。
- 副本和Leader同时故障。
- 副本先行重启,旧Leader没有重启,副本被选为新Leader。
- 新Leader收到一条记录m3写入,更新HW=1。
- 旧Leader重启,向新Leader同步数据,发现HW=1,认为已经同步,实际数据不一致。
Kafka Epoch
Epoch解决高水平截断问题(0.11+之后的改进)
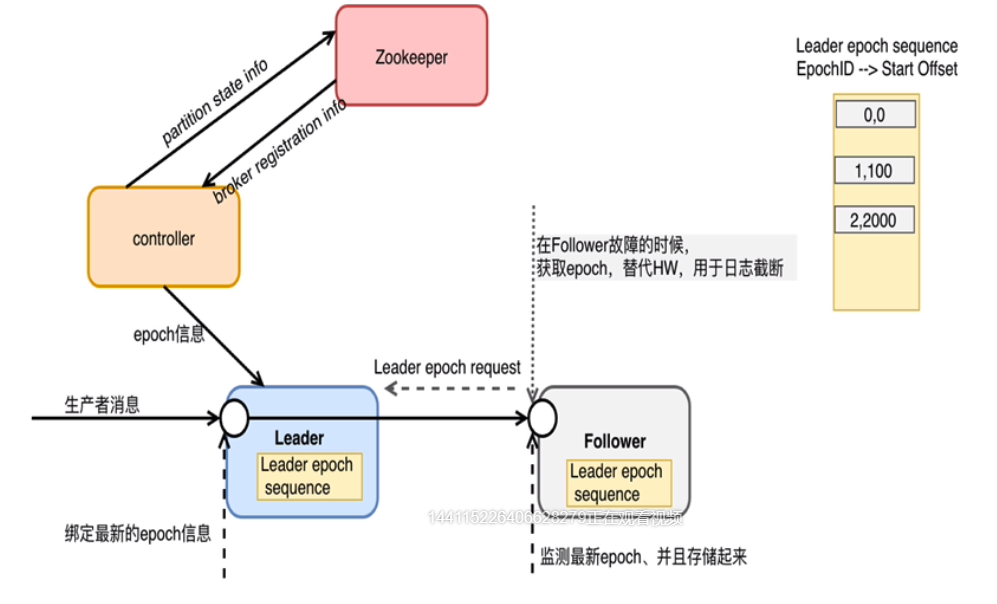
- 控制器controller负责管理epoch信息,并存储在zookeeper中。
- 控制器将epoch信息同步给Leader,也就是LeaderEpoch。
- 每次Leader接收到Producer的消息时,使用LeaderEpoch标记Message。
- 副本主动同步获取LeaderEpoch编号,替换HW的标记,作为消息的截断。
- 该epoch信息还会随着每一次LeaderAndIsrRequest传递给每一个新的Leader。
改进点:消息格式改进,每个消息集都带有一个4字节的Leader Epoch号。在每个日志目录中,会创建一个新的Leader Epoch Sequence文件,在其中存储Leader Epoch的序列和在该Epoch中生成的消息的Start Offset。它也缓存在每个副本中,同时还缓存在内存中。
Follower -> Leader:首先将新的Leader Epoch和副本的LEO添加到Leader Epoch Sequence序列文件的末尾并刷新数据。给Leader产生的每个新消息集都带有新的Leader Epoch标记。
Leader -> Follower:如果需要从本地的Leader Epoch Sequence加载数据,将数据存储在内存中,给相应的分区的Leader发送Epoch请求,该请求包含最新的EpochID,Start Offset信息(历史信息)。Leader接收到信息以后返回该EpochID所对应的Last Offset信息。该信息可能是最新的EpochID的Start Offset或者是当前EpochID的Log End Offset信息。
Kafka Eagle
Kafka监视系统,在github上直接安装Kafka-eagle-web就可以。
Kafka-Eagle Github
Kafka Streaming
Kafka Streaming也是一种实时在线流处理框架,相比较于其他的专业流处理框架Storm,Spark Stream,Flink等,它运行于应用端,不需要独立的服务器去运行它,具有简单,入门要求低,部署方便等优点。
特点
- Kafka Streaming提供了一个简单轻量级的lib库,可以非常方便的集成到任何Java项目中。
- 除了Kafka外,没有任何外部依赖。
- 利用Kafka的分区模型支持水平拓展和保证顺序性。
- 通过可容错的state store实现高效的状态操作(windowed joins and aggregations)。
- 支持exactly once一次处理语义(即幂等写)。
- 支持消息记录级的处理,实现毫秒级的延迟。
- 提供High-Level的Stream DSL(类似于Spark的map/group/reduce)和Low-Level的Processor API(类似于Storm的spout和bolt)。
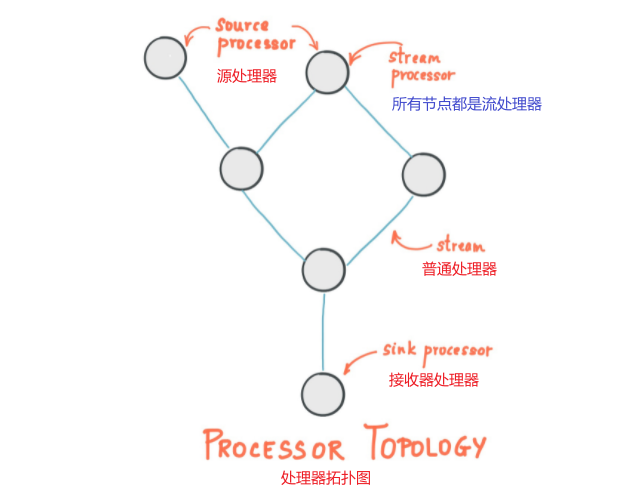
流处理拓扑
- Stream(流):流是Kafka Streams中最重要的抽象,代表了一个无界的,不断更新的数据集。流是不可变数据消息的有序、可重播和容错序列,其中数据被定义为键值对。
- Stream Processing Application(流处理应用):是使用了Kafka Streams库的应用,它通过定义一个或多个**processor topologies(处理器拓扑)**定义其计算逻辑,其中处理器拓扑是由流(边缘)连接的流处理器(节点)的图。
- Stream Processor(流处理器):是拓扑流图中的一个节点,表示了一个处理步骤,通过一次从拓扑中的上游处理器接收一个输入消息,对其应用操作,来转换流中的数据,并且随后可以向其下游处理器生成一个或多个输出消息。
拓扑中有2个特殊的处理器:
- Source Processor(源处理器):源处理器没有任何上游处理器,通过使用来自一个或多个Kafka Topic的记录,并将这些消息转发到其下游处理器,从而从一个或多个Kafka Topic生成一个输入到其拓扑的流。
- Sink Processor(接收器处理器):接收器处理器没有任何的下游处理器,它将所有从上游处理器接收到的消息发送到指定的Kafka Topic。
- Normal Processor(普通处理器):普通处理器既可以在处理中访问其他远程系统,处理后的结果可以流回Kafka或写入外部系统。
处理器拓扑图:
Kafka Streams提供了2种方法来定义流处理拓扑结构:
- Kafka Streams DSL:上层提供了常用的数据转换操作,例如
map,filter,join和aggregations。- Processor API:下层允许开发人员自定义处理器以及与state store进行交互。
时间
流处理中一个关键方面是时间的概念,以及如果对其进行建模和集成。例如,某些操作(Windowing)是基于时间边界定义的。
流中常见的时间概念是:
- Event Time:事件时间即事件或消息发生的时间点,最初是发生在源头上的时间。
- Processing Time:处理时间即事件或消息恰好由流处理应用程序处理的时间点,也就是消费消息时的时间点,处理时间可能比原始事件时间晚。
- Ingestion Time:接收时间即Kafka Broker将事件或数据消息存储在Topic分区中的时间点,与Event Time的差异在于,Ingestion Time是在Kafka Broker将消息添加到目标Topic时生成的,不是在源头创建消息时生成的。一条没有被处理过的消息没有Processing Time,但是有Ingestion Time。
Event Time和Ingestion Time的选择实际上是通过配置Kafka完成的:从Kafka0.10.x起,时间戳自动嵌入到Kafka消息中,即入门里介绍的timestamp,这些时间戳表示Event Time或Ingestion Time。可以在Broker级别或每个Topic上上指定相应的Kafka配置。
每当Kafka Streams应用将记录写入Kafka时,它将为这些新消息分配时间戳,分配方式取决于上下文:
- 当通过处理某些消息(例如
context.forward()在process()函数调用中触发)来生成新的输出消息时,输出消息时间戳会直接从输入消息时间戳继承。- 当通过周期性函数来生成新的输出消息时(
Punctuator#punctuate()),输出消息时间戳定义为context.timestamp()流任务的当前内部时间。- 对于
aggregation将是取所有消息中最大的时间戳。
对于aggravation,join时间戳的计算方式使用一下规则:
- 对于具有左右输入记录的
join(stream-stream,table-table),将为输出消息的时间戳分配为max(left.ts, right.ts)。- 对于
stream-join,将为输出消息的时间戳分配为stream的时间戳。- 对于
aggregation,针对全局(非窗口式)或每个窗口内计算所有消息上max的时间戳。- 对于无状态操作,将传递输入消息的时间戳。
流表二重性
几乎任何流处理技术都需要为流和表提供支持,因为大部分情况下,我们都是需要数据库的。Kafka提供了流表二重性的性质,即流可以当做表来看待,表也可以当做流来处理。
流表二重性:
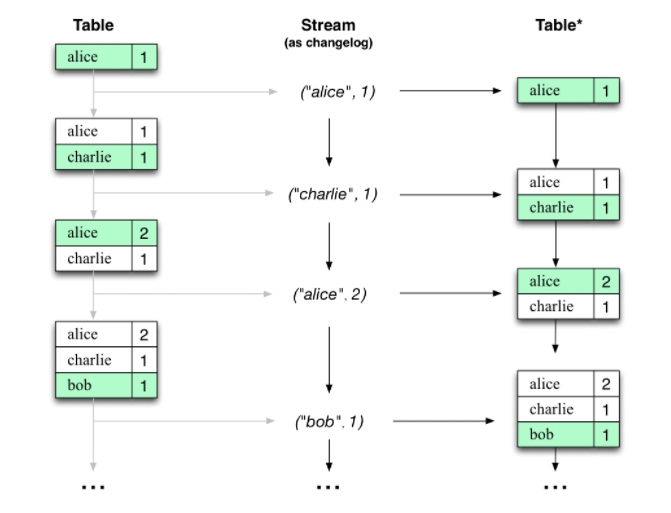
- 流 -> 表:流可以视为表的更改日志,流中的每个消息都捕获表的状态更改。因此流是变相的表,并且通过从头到尾重现更改日志以重建表,可以很容易的将其变成表。
- 表 -> 流:表在某个时间点可以视为流中的每个键的最新值的快照(流的数据记录是键值对)。因此,表是变相的流,并且可以通过迭代表中的每个键值条目将其轻松转换为流。
Aggregation
一个聚合操作需要一个输入流或表,并且由多个输入消息组合为单个输出消息产生的新表。
Windowing
窗口允许用户控制以具有相同密钥组消息的状态操作,如aggregations或joins窗口。使用窗口时,可以为窗口指定grace period,它控制Kafka Streams将等待给定窗口多长时间的无序消息记录。如果超过了该期限,则消息记录被丢弃,并且不会在窗口中进行处理。
State Store
Kafka Streams提供了State Store,可以由流处理应用使用它来存储和查询数据。在执行有状态操作时,这是很重要的功能。可以通过API访问state store来存储和查询所需要的数据。Kafka Streams为本地state store提供容错和自动恢复。
乱序处理
在Kafka Streams中,有两个原因可能导致数据时间戳相对于它们的到达顺序混乱:
- 在主题分区中,消息记录的时间戳及其offset可能不会单调增加。由于Kafka Streams始终会尝试按照offset顺序处理topic分区中的消息记录,因此它可能导致在相同topic中具有较大时间戳(但offset较小)的消息比具有较小时间戳(但offset较大)的消息要早处理。
- 在可能正在处理多个topic分区的流任务中,如果用户将应用程序配置为不等待所有分区都包含一些缓冲的数据,并从时间戳最小的分区中选取来处理下一条消息记录,则稍后再处理某些消息记录时如果是为其他topic分区获取的,则它们的时间戳可能小于从另一个topic分区获取的已处理消息记录的时间戳。
对于无状态操作,无序数据不会影响处理逻辑,因为一次只考虑一个消息,而无需查看过去处理消息的历史记录;但是对于有状态操作(例如aggregation和join),乱序数据可能会导致处理逻辑不正确。如果用户希望处理此类乱序数据,则通常需要允许其应用程序等待更长的时间,同时在等待时间内记录其状态,即在延迟,成本和正确性之间做出权衡决策。
但是对于join,某些乱序数据无法通过增加Streams的延迟和成本来处理:
- 对于Stream-Stream连接:所有三种类型(内部,外部,左)都可以正确处理乱序记录,但是对于左联接,结果流可能包含不必要的leftRecord-null;对于外部联接,结果流可能包含不必要的leftRecord-null或null-rightRecord。
- 对于Stream-Table连接:不处理无序记录(即,Streams应用程序不检查无序记录,而仅以偏移顺序处理所有记录),因此可能会产生不可预测的结果。
- 对于Table-Table连接:不处理无序记录(即,Streams应用程序不检查无序记录,而仅以偏移顺序处理所有记录)。但是,联接结果是变更日志流,因此最终将保持一致。
基本架构
架构示意图:
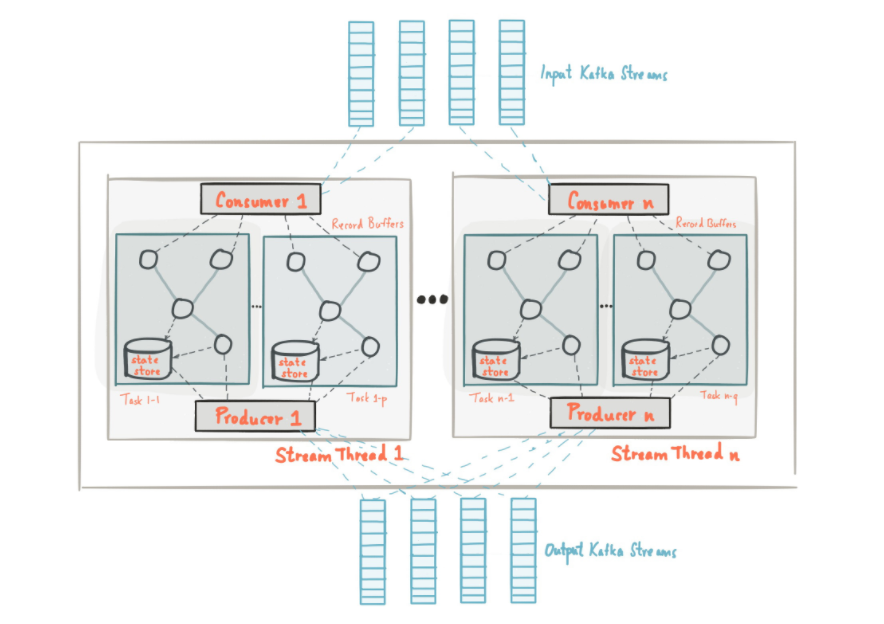
流分区(Stream Partitions)和任务(tasks)
Kafka的消息传递层对数据进行分区以进行存储和传输。Kafka Streams对数据进行分区以进行处理。在这两种情况下,这种分区都可以实现数据局部性,弹性,可伸缩性,高性能和容错能力。Kafka Streams使用分区和任务的概念作为基于Kafka Topic分区的并行模型的逻辑单元。在并行性方面,Kafka Streams和Kafka之间存在紧密的联系:
- 每个流分区都是数据消息记录的完全有序序列,并映射到Kafka Topic分区。
- 一个数据消息记录的流映射到Kafka Topic中的一个消息。
- 数据消息记录的
keys决定了Kafka流和Kafka流中的数据分区,即如何将数据路由到Topic内的特定分区。
线程
Kafka Streams允许用户配置该库可用于并行化应用程序实例中的处理的线程数。每个线程可以使用其处理器拓扑独立执行一个或多个任务。
容错能力
Kafka Streams建立在Kafka本地集成的容错功能的基础上。对于每个State Store,它维护一个复制的变更日志Kafka Topic,在其中跟踪任何状态更新。这些变更日志Topic也已分区,因此每个本地State Store实例以及访问该存储的任务都有自己的专用变更日志Topic分区。
如果任务在发生故障的计算机上运行并在另一台计算机上重新启动,则Kafka Streams通过在恢复对新启动的任务的处理之前重现相应的变更日志Topic分区,来保证将其关联的State Store恢复到故障之前的内容。所以故障处理最终对用户是完全透明的。
小结
- 高水位截断的问题?
主要是0.11版本之前,会发生数据丢失和不一致的问题。主要发生在同步过程。(0.11+版本epoch已解决)
- Kafka Streams的能否处理乱序数据?
可以处理,但是对于Stream-Stream和Stream-Table下的
join可能存在一定的风险,需要考虑,Table-Stream也仅能保证最终一致性。
学习自:Kafka官方文档
- 本文链接:https://github.com/moexiong/moexiong.github.io/tree/master/2021/05/13/Kafka%20%E8%BF%9B%E9%98%B6%E7%9F%A5%E8%AF%86/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。