Kafka API使用
Kafka基础API
Kafka常用API介绍
KafkaAdminClient
AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG:Kafka服务器地址。
- create(Properties props):创建一个Kafka客户端连接。
- listTopics():获取所有的topic主题。
- createTtopics(Collection<NewTopic> topics):批量创建topic。这个方法是一个异步方法,所以我们创建后的主题无法立刻查询到。可以使用创建后的主题结果createTopicResult.all().get()来同步等待主题的创建。
- deleteTopics(Collection<String> topics):批量删除topic。也是异步方法,同理也可以同步去等待执行完成。
- describeTopics(Collection<String> topics):批量查看topic的详细信息。得到一个DescribeTopicsResult。
- close():关闭连接。
KafkaProducer
ProducerConfig.BOOTSTRAP_SERVERS_CONFIG:Kafka服务器地址,作为生产者使用。
ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG:key的序列化方式,可以自定义实现序列化方式。
ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG:value的序列化方式,可以自定义实现序列化方式。
ProducerConfig.PARTITION_CLASS_CONFIG:自定义分区,需要实现Partitioner接口。生产者投递消息时,默认是采用轮询的方式投递消息。
- 构造:构造出将准备向某一个topic投递的生产者。
- send(ProducerRecord<String, String> record):发送一个消息,消息有不同的构造,可以自己定义key,value和时间戳。
- flush():清理数据发送缓冲区。
- close():关闭生产者连接。
KafkaConsumer
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG:Kafka服务器地址,作为消费者使用。
ConsumerConfig.KEY_SERIALIZER_CLASS_CONFIG:key的序列化方式,可以自定义实现序列化方式。
ConsumerConfig.VALUE_SERIALIZER_CLASS_CONFIG:value的序列化方式,可以自定义实现序列化方式。
ConsumerConfig.GROUP_ID_CONFIG:消费者组的ID。
- subscribe(Pattern reg):订阅对应正则表达式下的主题,当然可以订阅多个。
- assign(List<TopicPartiton> topicPartitions):订阅一个topic的某些分区。
- poll(Duration timeout):多长时间去抓取消息记录,获取一个ConsumerRecord消息。
ProducerInterceptor
- onSend(ProducerRecord record):用户在向topic中投递信息后可以进行一些处理。
- onAcknowledgement(RecordMetaData data, Exception ex):data是发送成功时的topic消息处理的回调信息。
- close():不咋用
- configure(Map<String, ?> configures):不咋用
Kafka高级API
Offset自动控制
Kafka消费者对于未订阅的topic的offset的时候,也就是系统并没有存储该消费者的消费分区的记录信息,默认Kafka消费者的首次消费策略是:latest。
auto.offset.reset = latest
- earliest:自动将偏移量重置为最早的偏移量。
- latest:自动将偏移量重置为最新的偏移量。
- none:如果没有找到消费者组的先前偏移量,则会向消费者抛出异常。
Kafka消费者在消费数据的时候默认会定期的提交消费的偏移量,这样就可以保证所有的消息至少可以被消费者消费1次,可以通过一下参数来进行配置:
enable.auto.commit = true
auto.commit.interval.ms = 5000
如果需要自己手动控制offset的提交,可以关闭offset的自动提交,但是要注意手动提交时,提交的偏移量永远要比本次消费的偏移量+1,因为提交的偏移量是Kafka消费者组下一次将要获取的数据位置。
KafkaConsumer
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG:手动去配置offset的提交方式,默认是latest。
ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG:offset的自动提交间隔,默认是5s。
ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG:是否开启自动提交,默认是true。
- commitAsync(Map<TopicPartition, OffsetAndMetadata> offsets, OffsetCommitCallback callback):异步手动提交偏移量信息。
Ackes&Retries
Kafka生产者在发送完一个消息后,要求Broker在规定的时间内应答Ack,如果没有应答,那么Kafka生产者会尝试在n次内重新发送消息。
acks = 1
- 1:Leader会将Record写到其本地日志中,但会在不等待所有Follower的完全确认的情况下做出响应。在这种情况下,如果Leader在确认记录成功后立即宕机,发生在Follower复制记录之前,则记录丢失。
- 0:生产者根本不会等待服务器的任何确认,该记录将立即发送添加到套接字缓冲区中并视为已发送。在这种情况下,不能保证服务器已收到记录。不可靠。
- -1(all):意味着Leader将等待全套同步副本确认记录。这保证了只要至少一个同步副本仍处于活动状态,记录就不会丢失,这是最有力的保证。慢。
如果生产者在规定的时间内,并没有得到Kafka的Leader的Ack应答,Kafka可以开启retries机制,重试。
request.timeout.ms = 30000
retries = 2147483647
应答过程时序:
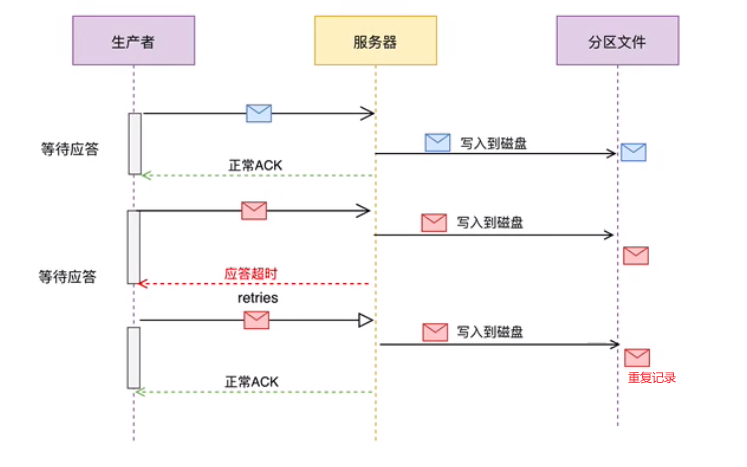
Leader在记录完成后,响应丢失,重试时发生消息记录重复。
KafkaProducer
ProducerConfig.ACKS_CONFIG:acks配置,默认是1。
ProducerConfig.RETRIES_CONFIG:重试的最大次数,默认是2147483647次,几乎无限重试。
ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG:每次重试的超时检测时间,默认是30s。
幂等写
幂等是针对生产者角度的特性,可以保证生产者发送的消息不会丢失,不会重复,实现的关键点是服务端可以区分请求是否重复,过滤掉重复的请求。但是只能保证在一个分区内的消息发送的原子性。
- 唯一标识:要想区分请求是否重复,请求中就得有唯一标识。
- 记录下处理过的请求标识:每次接收到新请求时,会把请求标识与处理记录做比较,如果是重复请求,就直接拒绝掉。
幂等又称为exactly once。要停止多次处理同一消息,必须将其持久化到Kafka Topic中仅一次,在初始化期间,Kafka会给每个生产者生成一个唯一的ID称为Producer ID或PID。
PID和序列号与消息捆绑在一起,然后发送给Broker。由于序列号从零开始且单调递增,因此,仅当消息的序列号比该PID/TopicPartition对中最后提交的消息正好大1时,Broker才会接受该消息,否则Broker认为是重复消息。
enable.idempotence = false
注:如果要开启幂等性,要求必须开启acks = all和retries = true。
消息重复的解决:
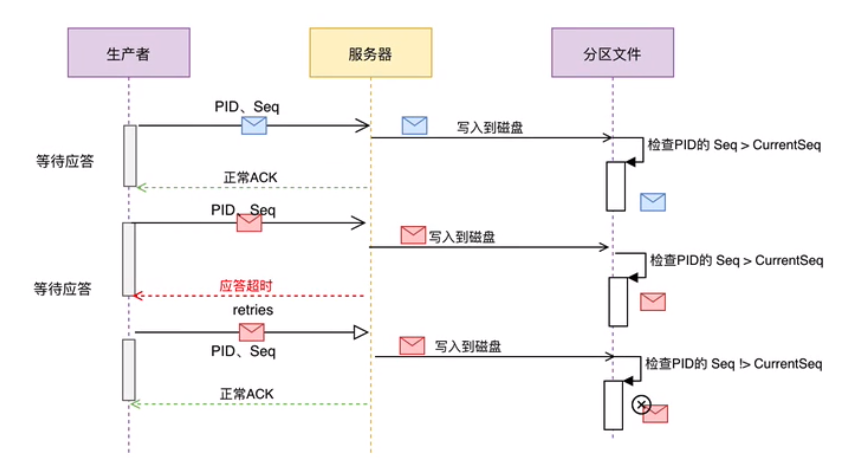
KafkaProducer
ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG:幂等性配置,默认是false。(为true时一定要acks=all和retries=true)
ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PRE_CONNECTION:最大允许等待数,设置为1时,可以保证只要有1个没有确认成功,就会阻塞,不会接收下一个,保证有序。
生产者事务
对比幂等性,幂等只能保证一个分区内的消息的发送的原子性,而Kafka的事务操作可以保证在一个topic内的多条消息即多个分区间的消息完整性。事务通常分为2类:
- 生产者事务:仅仅控制生产者的一些特性,即消息的发送性质。批量提交类似DB,只要有一个失败即全部失败。标记失败的数据。
- 生产者&消费者事务:即充当消费者又充当生产者的情况,保证从消息的消费到消息的发送的整个流程的原子性。包括消费时offset的撤销和发送的数据标记。
isolation.level = read_uncommitted- read_committed:读已提交的数据,开启事务时,消费者端一定是开启read_committed的,不然就没有意义了。
- read_uncommitted:读未提交的数据,就相当于不开启事务。
Kafka事务与数据库事务不太一样的地方:当事务失败时,数据并不会回滚,仍然会把消息写入到topic的分区中,但是事务失败的时候会将消息标记为事务失败,因此如果开启了事务的隔离别,就可以防止消费者读到这些已经被标记为失败的数据。
开启生产者事务的时候,只需要指定transactional.id属性即可,一旦开启了事务,默认生产者就会自动开启幂等性,而且要求所有生产者的transactional.id的取值一定要是唯一的,同一时刻只能有一个transactional.id存在,其他的将会被关闭。
KafkaProducer
ProducerConfig.TRANSACTIONAL_ID_CONFIG:生产者事务ID配置,必须保证全局唯一。(否则相同的ID中只会有一个生效)
ProducerConfig.BATCH_SIZE_CONFIG:批处理大小,同一个事务内最多可以处理的消息个数。默认是16384。
ProducerConfig.LINGER_MS_CONFIG:最大等待时间间隔,如果时间到了数量没有达到最大允许的批处理数量,直接执行。
- initTransactions():初始化事务配置。
- beginTransaction():开启事务。
- commitTransaction():提交事务。
- abortTransaction():终止事务。
- sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets, String groupId):提交消费者的偏移量。
KafkaConsumer
ConsumerConfig.ISOLATION_LEVEL_CONFIG:读的事务隔离级别,开启事务后一定要设置为read_committed,不然等于没开。
小结
- 为什么会发生丢消息,不可靠?
当ack确认为1时:Leader在确认记录后突然故障,此时副本因子还没有同步时,消息丢失。
当ack确认为0时:不等待确认生产者投递消息可能未送达服务器,也会消息丢失。
- 什么情况下会有重复数据产生?
确认时响应如果丢失,会导致retries机制重试,然后写多份。(幂等写已解决,但默认没开)
- 没有重复数据却消费多次或没有消费?
可能是offset提交出现问题
- 本文链接:https://github.com/moexiong/moexiong.github.io/tree/master/2021/05/12/Kafka%20API%E4%BD%BF%E7%94%A8/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。