Redis 基础知识
Redis 介绍(百度)
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
Redis 对象
Redis的key只是字符串类型,但是value却支持多种对象类型,server.h中redisObject的结构定义为:
1 | typedef struct redisObject { |
一个 RedisObject 对象头共需要占据 16 字节的存储空间。
注:均基于Redis6.2.3版本源码分析。
| 数据类型 | type取值 | 说明 |
|---|---|---|
| OBJ_STRING | 0 | 字符串对象 (实际可以为整型,浮点型以及字符串) |
| OBJ_LIST | 1 | 列表对象(实际队列,元素可以重复,支持FIFO原则,对比Java的List) |
| OBJ_SET | 2 | set (不可重复的集合,对比Java的Set) |
| OBJ_ZSET | 3 | sorted set (有序集合) |
| OBJ_HASH | 4 | hash (Hash表) |
| OBJ_MODULE | 5 | 模块对象(在RDB文件中的编码形式为,具有64位的模块ID,其中54位为模块特定签名,10位为编码版本) |
| OBJ_STREAM | 6 | 流对象(5.0版本以后新增的,为了更好的当做消息队列使用) |
| 编码类型 | encoding取值 | 说明 | Object encoding命令输出 |
|---|---|---|---|
| OBJ_ENCODING_RAW | 0 | 简单动态字符串 | raw |
| OBJ_ENCODING_INT | 1 | long类型的整数 | int |
| OBJ_ENCODING_HT | 2 | 字典 | hashtable |
| OBJ_ENCODING_ZIPMAP | 3 | 压缩字典 | 无了 |
| OBJ_ENCODING_LINKEDLIST | 4 | 双端链表 | 无了 |
| OBJ_ENCODING_ZIPLIST | 5 | 压缩列表 | ziplist |
| OBJ_ENCODING_INTSET | 6 | 整数集合 | intset |
| OBJ_ENCODING_SKIPLIST | 7 | 跳跃表 | skiplist |
| OBJ_ENCODING_EMBSTR | 8 | embstr编码的简单动态字符串 | embstr |
| OBJ_ENCODING_QUICKLIST | 9 | 快速列表 | quicklist |
| OBJ_ENCODING_STREAM | 10 | 流 | stream |
字符串对象(String)
字符串对象支持的存储格式有3种:
- OBJ_ENCODING_INT:当存储的是数值类型的时。
- OBJ_ENCODING_EMBSTR:当存储的是字符串且长度小于等于44字节时。
- OBJ_ENCODING_RAW:当存储的是字符串且长度大于44字节时。
1 | struct __attribute__ ((__packed__)) sdshdr[5|8|16|32|64] { |
SDSHDR的结构大致如下:
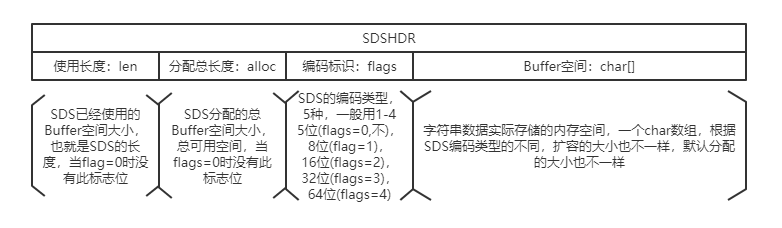
flags=0的场景有待验证,从源码中看是定长,与C字符串类似,可能用作常量?
横向表示为内存地址空间。
OBJ_ENCODING_INT
如果要存储一个数值为100的字符串进去
INT示意图:

- 数值类型的值,直接存储在*ptr指针所指向的内存,没有额外的空间引用,不需要使用SDSHDR结构。
OBJ_ENCODING_EMBSTR
如果要存储一个Hello进去(小于44字节)。
1 |
|
EMBSTR示意图:

- 当字符串长度小于等于44字节时,会以EMBSTR编码的SDSHDR类型存储。
- SDSHDR的内存分配是与REDIS_OBJECT一起申请的,所以它们是连续的空间内存,一次内存分配即可完成。
- EMBSTR类型一般不修改,如果要修改,要么长度仍小于44字节重建,要么长度大于44字节类型变换为RAW。
OBJ_ENCODING_RAW
如果存储一个大于44bytes的字符串abcd...(省略)。
RAW字符串示意:

- 当字符串长度大于44字节时,会以RAW编码的SDSHDR类型存储。
- SDSHDR的内存分配是单独的一次,这是和EMBSTR不一样的地方,需要两次内存分配才行,不连续。
- 预留空间充足时,字符串改变无需重写分配内存,不够时需要重建。
列表对象(List)
列表对象可支持的存储格式有2种:
- OBJ_ENCODING_ZIPLIST:当列表中对象少(小于128个),仅有INT或短字符串(小于64bytes)时,使用压缩列表。
- OBJ_ENCODING_QUICKLIST:当列表中的对象多,或字符串类型长,变动频繁时,用快速压缩列表。
OBJ_ENCODING_ZIPLIST
ZIPLIST的结构定义如下:
1 | typedef struct zlentry { |
压缩列表示意:
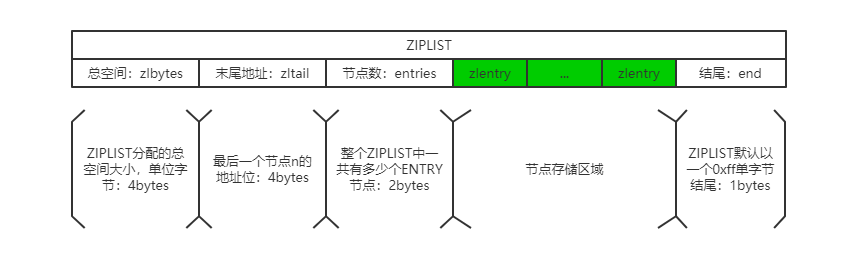
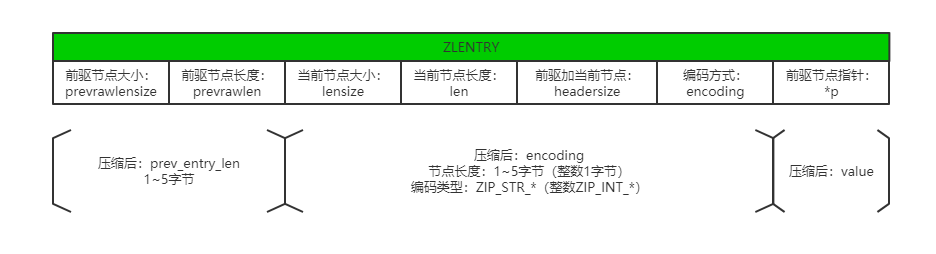
- 压缩列表本是单向链表,但是由于内存空间存储的连续性,使得可以从header向tail遍历,所以可以看做双向链表,弥补了单向链表的查询弊端,但是修改会重新分配内存空间以维护连续性,所以修改的效率不一定是O(1),列表越大,效率越低。
- 由于会分配一个节点会记录其前驱的长度,当节点长度小于255字节时,默认只会采用一个bytes去记录节点的前驱长度,为了节省内存,但是当有一个节点大于或等于255字节时,一个bytes不够,需要扩容为5个bytes来记录前驱节点的长度,为了不频繁更新,redis直接进行连锁更新,将后续所有节点的前驱长度记录扩容为5bytes,若后续节点都是250~253bytes,最差情况插入头节点大于等于255,引发全部节点的内存重新分配,删除同理。
- redis为了防止发生数组抖动,一会儿扩一会儿缩这种,不处理因为节点的变小而引发的连锁更新,防止出现反复的缩小-扩展(flapping,抖动)。
OBJ_ENCODING_QUICKLIST
快速列表由压缩列表构成,类似于分段的思想,将其拆分为多组ZIPLIST。
快速列表的结构定义如下:
1 | typedef struct quicklist { |
快速列表示意:
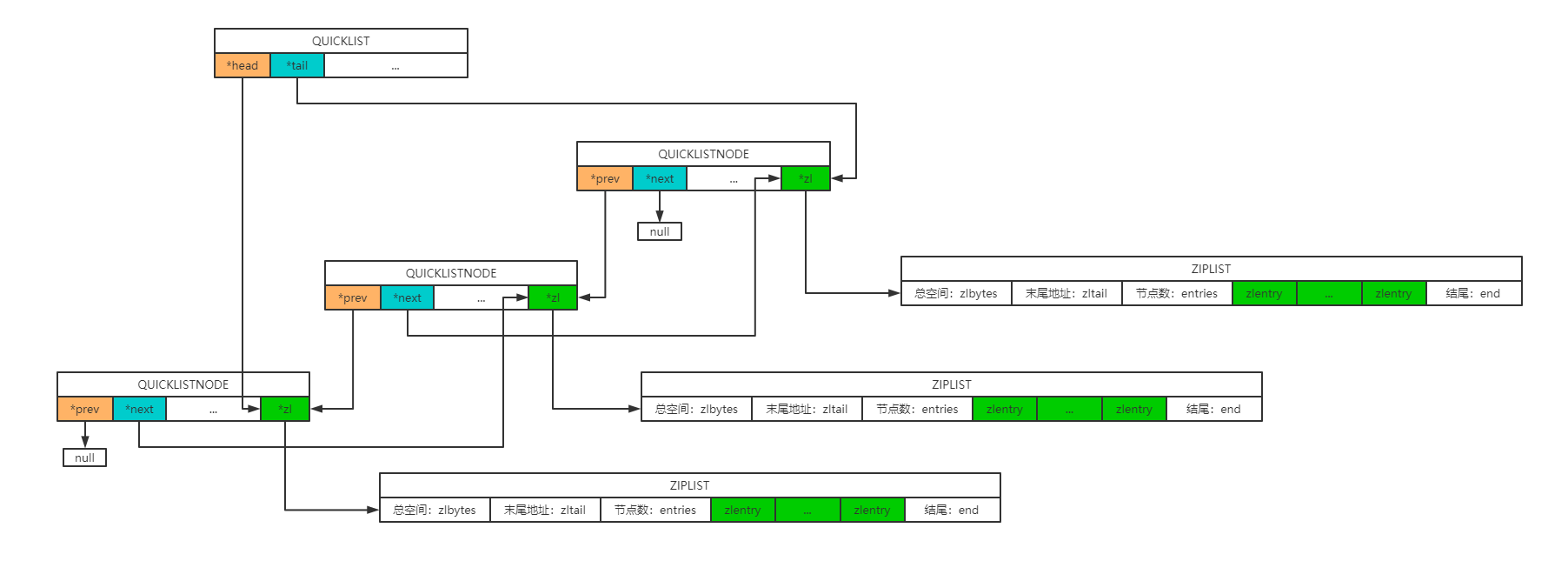
- 直接就是一个双向链表,进行插入或删除操作时非常方便,虽然复杂度为O(n),但是不需要内存的复制,提高了效率,而且访问两端元素复杂度为O(1)。
- 每个entry继承了ZIPLIST的优点,顺序存储,内存连续,利用二分查找,对于ZIPLIST的查找效率较高。
- 因为每个ZIPLIST都是小节点,默认不超过8kb,所以发生连锁更新的情况也会比较小。
集合对象(Set)
集合对象可支持的存储格式有2种:
- OBJ_ENCODING_INTSET:当集合中的值全是整数,或者对象数量不超过512个时,采用整数集合(IntSet)。
- OBJ_ENCODING_HT:不满足上述任一条件后,采用字典(HashTable)。
OBJ_ENCODING_INTSET
整数集合的结构定义如下:
1 | typedef struct intset { |
整数集合示意:
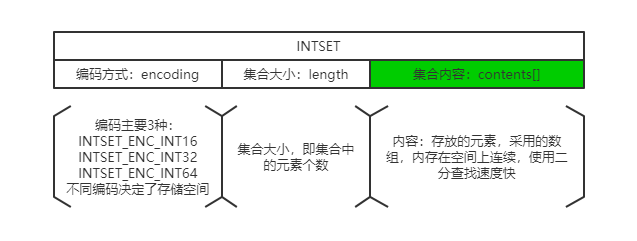
- 采用了数组作为存储结构,有序。使用二分查找快速定位元素。
- 不同编码会影响集合的空间申请大小,当整数由小编码转大编码时,将数组扩容为大编码格式,需要扩容内存空间,反之则不会。道理同ZIPLIST的扩容,为了防止抖动。
OBJ_ENCODING_HT
HT即HashTable,也就是字典。
字典的结构定义如下:
1 | typedef struct dict { |
字典示意:
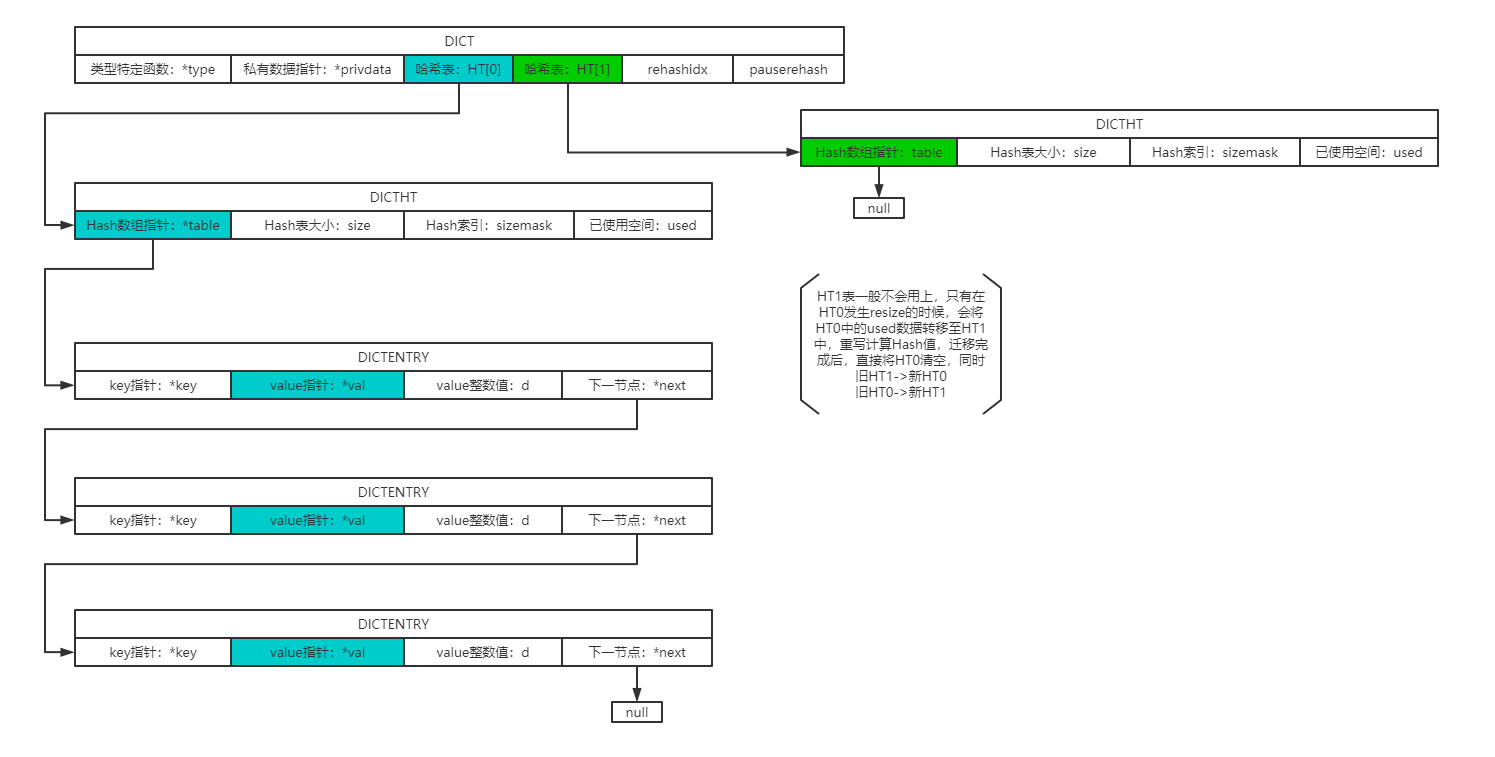
- 负载因子 = 哈希表当前保存节点数 / 哈希表大小。当没有执行BGSAVE或BGREWRITEAOF时,负载因子大于等于1时就会发送扩展操作。否则当负载因子大于等于5时才会发生扩展操作。当负载因子小于0.1时会发生收缩操作。
- 采用2张Hash表,渐进式扩展,不会明显降低当前hash表的访问效率。
有序集合对象(ZSet)
有序集合对象可支持的存储格式有2种:
- OBJ_ENCODING_ZIPLIST:压缩列表,同上所述。
- OBJ_ENCODING_SKIPLIST:跳跃表,类似于B*树,底层是一个双向链表,上层单向链表。
OBJ_ENCODING_SKIPLIST
跳跃表的结构定义如下:
1 | typedef struct zskiplist { |
跳跃表示意:
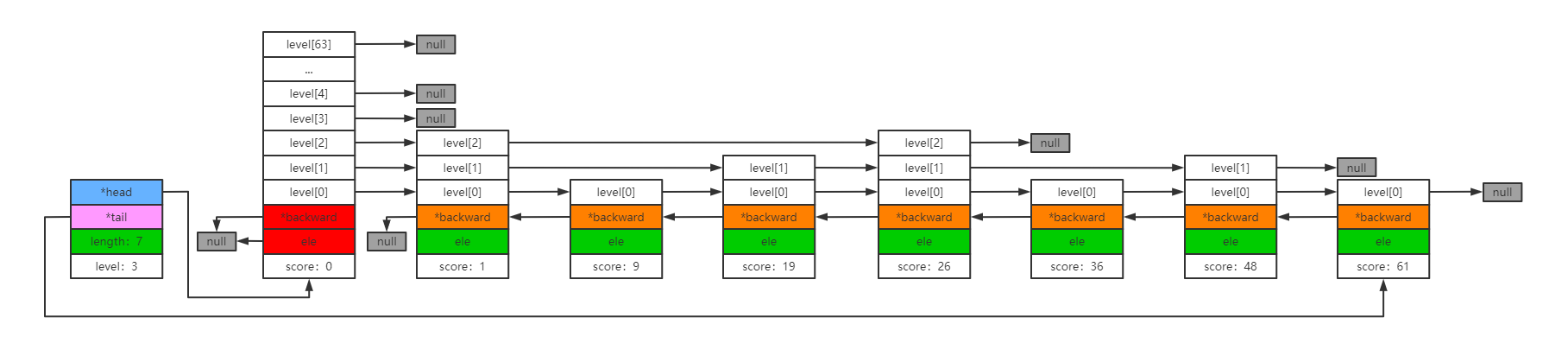
- 允许score重复,由ele数据内容来唯一标识一份数据。只有底层是双向链表,可以看做是level[0]的逆向链表。
- 有序,且能快速查找列表中的元素,O(logN)的时间复杂度。
- 插入和删除节点不会引起大范围的自平衡,只影响相邻节点。
哈希对象(Hash)
哈希对象可支持的存储格式有2种:
- OBJ_ENCODING_ZIPLIST:压缩列表,同上所述。
- OBJ_ENCODING_HT:字典,同上所述。
流对象(Stream)
流对象只有一种存储编码格式:
- OBJ_ENCODING_STREAM:消息流,配合rax基数树(前缀树)一起使用
OBJ_ENCODING_STREAM
1 | typedef struct stream { |
前缀树示意:
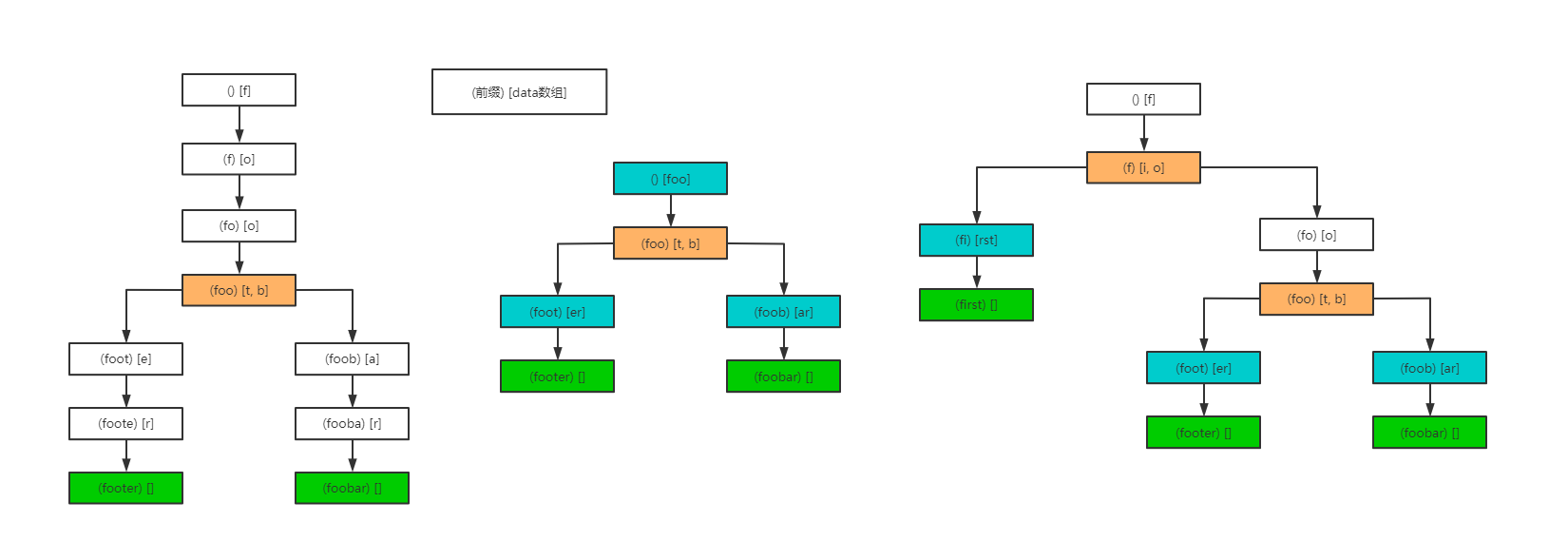
从左向右依次为,未压缩的rax树,压缩后的rax树,新增节点后的rax树变化。每个节点内容只存储压缩后的字符,当树出现分支时,由标记iscompr来标识当前data内容为非压缩节点,每个字符都有子节点(所以这就是为什么加入first之后,会有一个(fo) [o]出现,不合并到前面的分支或后面的分支,如果中间有超过一个的字符出现,那么也是会压缩的)。插入元素会导致节点分裂,同理,删除元素时又会再次将相同前缀的节点压缩。
所以上述最后一张图的内存结构如下所示:
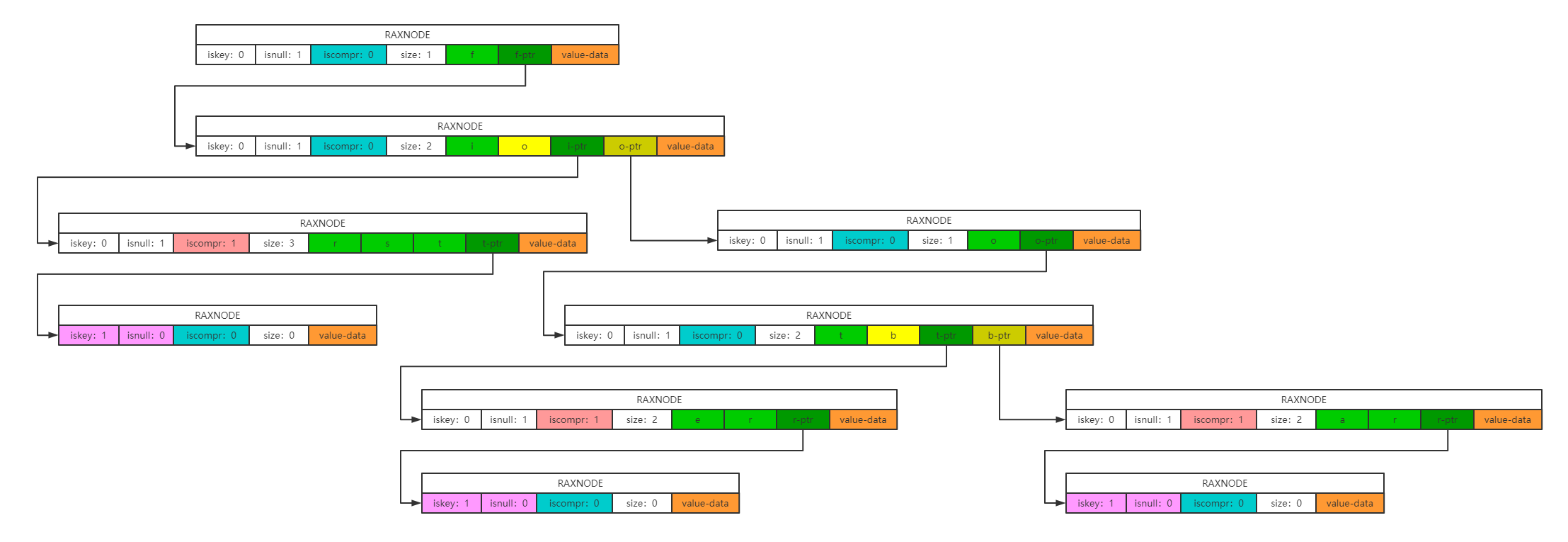
- 没有被压缩的节点,每个值都有一个子节点。
- 普通节点的iskey=0,isnull=1。表明当前节点不是实际值,只有最后一个节点才是,它的iskey=1,isnull=0。
- 被压缩的节点只有最后一个值作为指向子节点的指针。
Stream示意:
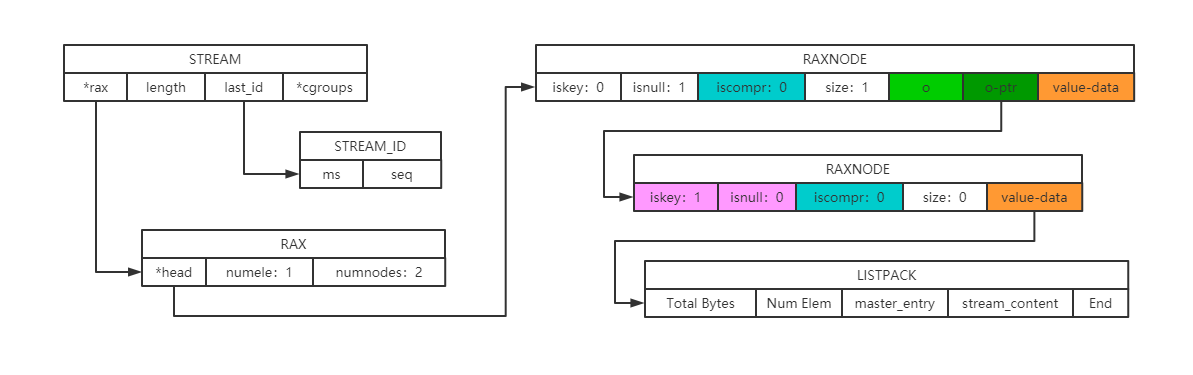
- rax最后一个值另外充当了listpack的指针,标识当前key指向的消息流的实际内容。
参考资料
Redis 6.2.3源码
redis 系列,要懂redis,首先得看懂sds(全网最细节的sds讲解)
redis源码分析-intset(整型集合)
Redis 压缩列表(ziplist)和快速列表(quicklist)
Redis五种数据类型详解
Redis数据结构——快速列表(quicklist)
Redis数据结构——dict(字典)
Redis radix tree源码解析
带你读《Redis 5设计与源码分析》之三:跳 跃 表
Redis5设计与源码分析 (第8章 Stream)
- 本文链接:https://github.com/moexiong/moexiong.github.io/tree/master/2021/05/25/Redis%20%E5%9F%BA%E7%A1%80%E5%AF%B9%E8%B1%A1/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。